
Background:
Many a times the business required to do few/lots of Transformation and even Analytics on data available within MongoDB. Many of them try to do it outside MongoDB due to various reasons, which typically requires the huge data movement, unprocessed data hopping and consuming network bandwidth or redundancy into various places like BI environment, Consuming application environment, Big Data environment etc. This seems ok, however moving towards current data privacy regulations (e.g. GDPR in Europe [1], World Economic Forum, and Personal Data [2] etc.), it becomes extremely feasible if the product provides the capability to perform it within the circumference of it.
MongoDB way of doing it:
MongoDB provides typically three ways of performing the transformation/analytics [3] i.e.
- Aggregation Pipelines
- Map-Reduce Functions
- Single Purpose Aggregation functions (or operations)
Actually the first two are real options of performing it and the third one is just the group of operations already created for some common aggregation processes on a single collection e.g. count, distinct etc. similar to SQL functions.
Currently, it is advised to use the aggregation pipeline mechanism over Map-Reduce for better efficiency and I will be publishing a separate post soon on “Aggregation Pipeline vs Map-Reduce in MongoDB”. (Keep watching upcoming posts 🙂 ……). As of now, just be informed that Map-Reduce relies on JS functions that are executed on top of JS engine (Currently “SpiderMonkey” is used since version 3.2) compared to Aggregation framework which directly used C++.
Aggregation Pipeline Method:
(If you already know about it then you can skip this and jump directly to “Time for Action” section to go through the use cases)
The method is very well depicted in below diagram and explained duly on MongoDB site as well. To add more on clarification, aggregation pipeline framework works in a way where data processing passes through multiple pipelines which transforms, enrich or narrow down data as it passes through these pipes.
Each pipeline is made up of stages which are evaluated or executed based on the stage operator used and the expressions involved within that stage.

So in above example, lines with $match and $group are two stages in below data processing pipeline. Technically “$match” and “$group” are aggregation pipeline stage operators and “$sum” is the aggregate pipeline expression operator.
This Post : In this post I will be explaining the simple and a little complex use case using the Aggregation pipeline method and Map-Reduce methodology shall be covered in a separate dedicated post which I shall be posting soon.
Time for Action:
Let’s go directly and get the feel of aggregation with some use cases. The use case consists of a sample JSON having collection of restaurants (restaurants_sample) in New York City in all of it boroughs (i.e. Manhattan, Queens Etc.). Each restaurant has a type of cuisine and multiple branches in different locations (boroughs) and each branch has evaluation record showing grades (date of evaluation, grade, score).
You can download the all the sample JSON data and the scripts used in this blog here.
Below here is a typical screen of Robo Mongo, explorer tool of MongoDB.
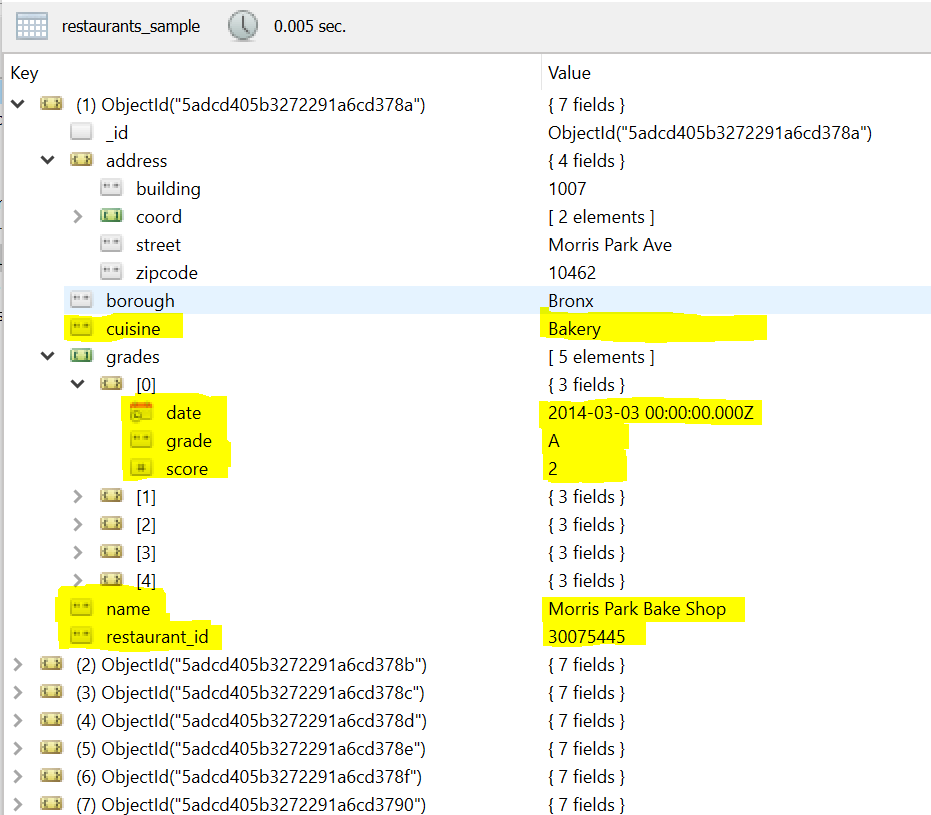
Use Cases
Use Case 1:
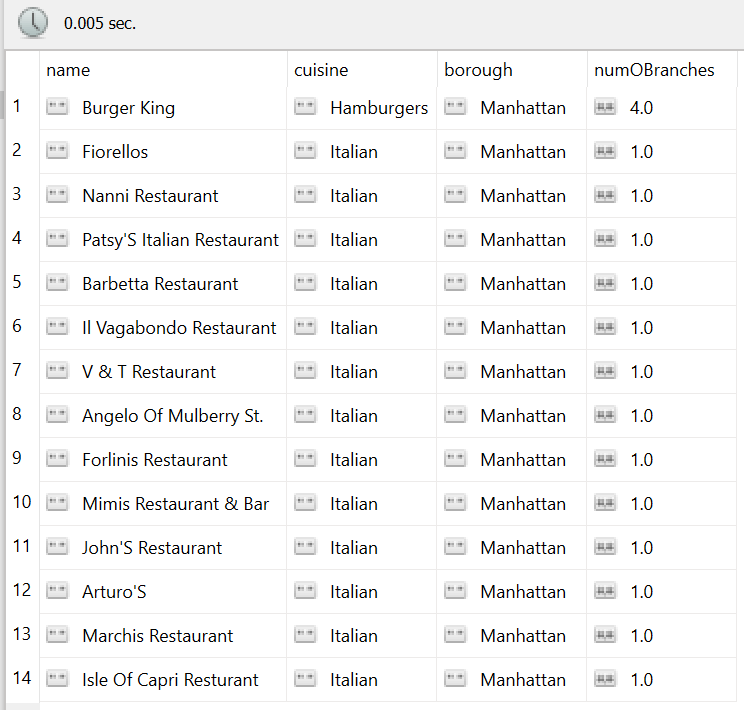
Transforming and aggregating the results of all the restaurants with cuisine “Hamburgers” or “Italian” within “Manhattan” and also showing number of branches in that borough.
Below here is the aggregation operation script consists of multiple stages to perform the required transformation.

Explanation of script – Use Case 1:
-
Line 2-4: Here “$match” stage refines and brings only those documents in pipeline which are required to process further. Now, those restaurants shall be processed in next stage which belong to borough “Manhattan” and having either “Italian” or “Hamburgers” cuisine.
-
Line 7 -10 : The records are then group by “_id” which is mandatory and other grouped fields (name, cuisine, borough) and expression for transformed field data “numOfBranches” to count the number of branches in this stage.
-
Line 13-18: In this stage, we select the fields which are required to be displayed as output so that other non usable fields can be removed for next stages in pipeline. Here, I have used it to beautify the output because if you execute it without this stage then you will get all the fields under “_id” object with auto generated value of “_id”. Here _id:0 removes the _id field from output.
-
Line 22-24: Finally, the last stage is sorting the results in descending order of “numOfBranches” field value.
Output – Use Case 1:
Use Case 2:
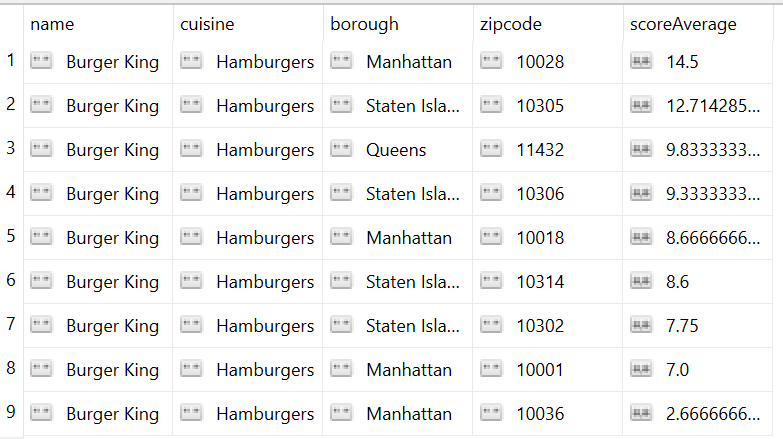
Transform to fetch the details of restaurant named “Burger King” with average score of each branch, along with its borough and the zip code of each restaurant including the calculated average score of each branch.
Below here is the script:
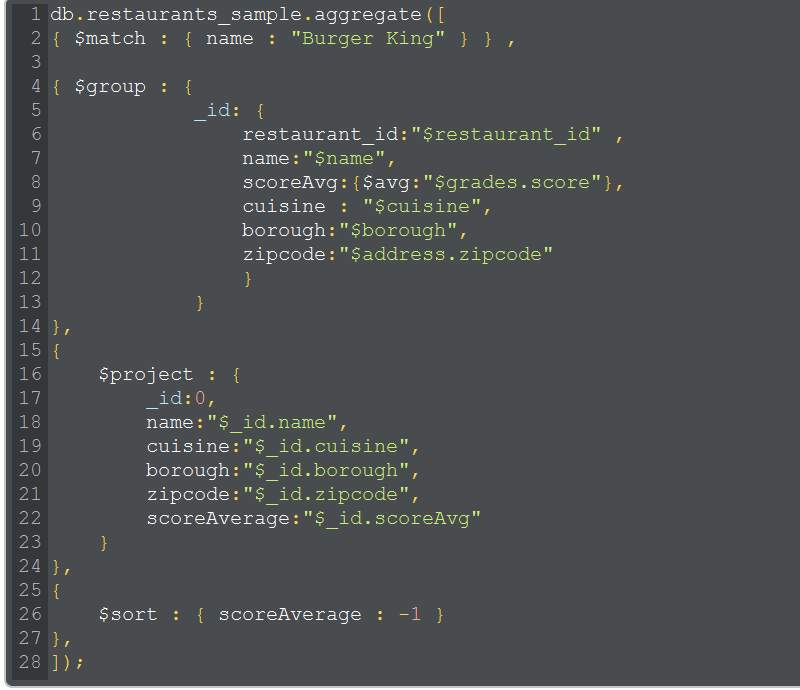
Explanation of script – Use Case 2:
Line 8 : Here, one can see other lines are similar to use case 1 except line 8 which has expression to evaluate the average of “score” field which is under “grades” object in each restaurant document.
Output – Use Case 2:
Use Case 3:
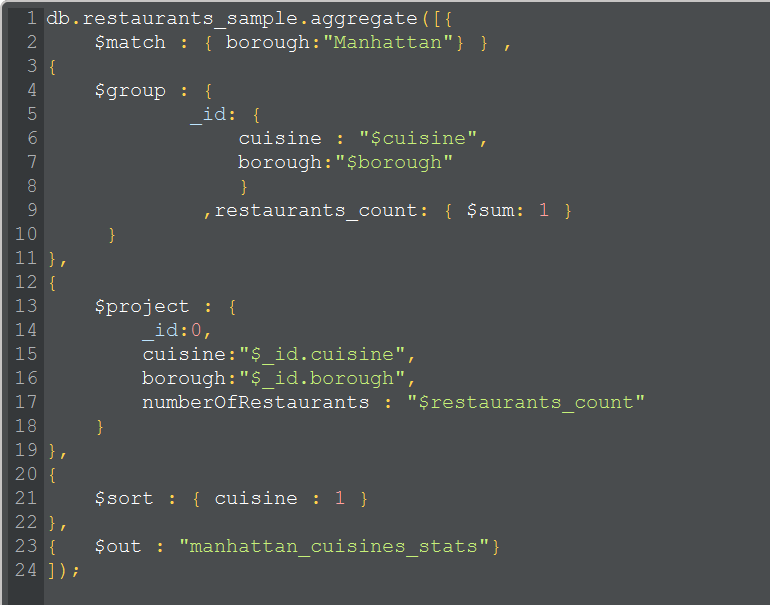
Aggregate all the cuisines and number of restaurant per cuisines in “Manhattan” borough. To make it little complex we will store the results in a different collection named “manhattan_cuisines_stats” so that it can be used by any BI or application for showing the statistics.
Below here is the script for use case 3:
Explanation of script – Use case 3:
Line 23 : Here all the script stages are similar except line 23 where the output of the aggregation result is stored in a new collection named “manhattan_cuisines_stats”.
Output – Use case 3:
In order to fetch the result of aggregation transformation performed in use case 3, one can fire “find” query over the new collection “manhattan_cuisines_stats”

References:
[1] European Commission (2016), The General Data Protection Regulation (GDPR) (Regulation (EU) 2016/679).
[2] World Economic Forum, Personal Data: The Emergence of a New Asset Class, 2011,
Disclaimer : All the views and opinion expressed in this website or blog are personal and belong solely to the author and does not represent any organization, institution, employer that the author may or may not be associated with in a professional or personal capacity.
